Recently, rasbt open-sourced Thunder, a new compiler for PyTorch. It can achieve a 40% speedup compared to regular PyTorch on LLM training tasks (e.g., Llama 2 7B). The Readme.md of the repo has this line “Works on single accelerators and in multi-GPU settings.”
In a forum that I’m part of, someone asked what was an accelerator? Hence wrote a small post on this.
Accelerators
Accelerators are the workhorses that a computing system needs to train and run machine learning models.
Machine learning workloads can be classified into:
- Training
- Inference
In an LLM, when inferring using a model, the generation happens in sequence - one token a time.
In this scenario, an accelerator such as GPU is used. Nowadays, there are many accelerators.
Accelerator glossary
CPU: Central Processing Unit
• GPU: Graphics Processing Unit: - Nvidia A100 - Nvidia H100 - AMD MI250 - Intel Arc
• HPU: Habana Gaudi AI Processor Unit - Intel Gaudi AI
• IPU: Intelligence Processing Unit - Graphcore
• MME: Matrix Multiplication Engine
• QPU: Quantum Processing Unit:
• RDU: Reconfigurable Dataflow Unit
• TPU: Tensor Processing Unit: - Google TPU
Spectrum in AI accelerators
If one reads the history of the GPUs, they can understand that GPUs where not designed with Machine learning workloads initially. As the market goes on, GPU creators and designers have been adapting for ML workloads and applications.
If one wants specialized AI accelerators, FPGA and ASIC vendors are also available thee days. While they can be very efficient, they also can be subject to lack of re-programmability and yield to locking such as Google’s TPU.
An illustrative figure can be like this that helps to understand the different AI accelerators spectrum can be seen in the picture below.
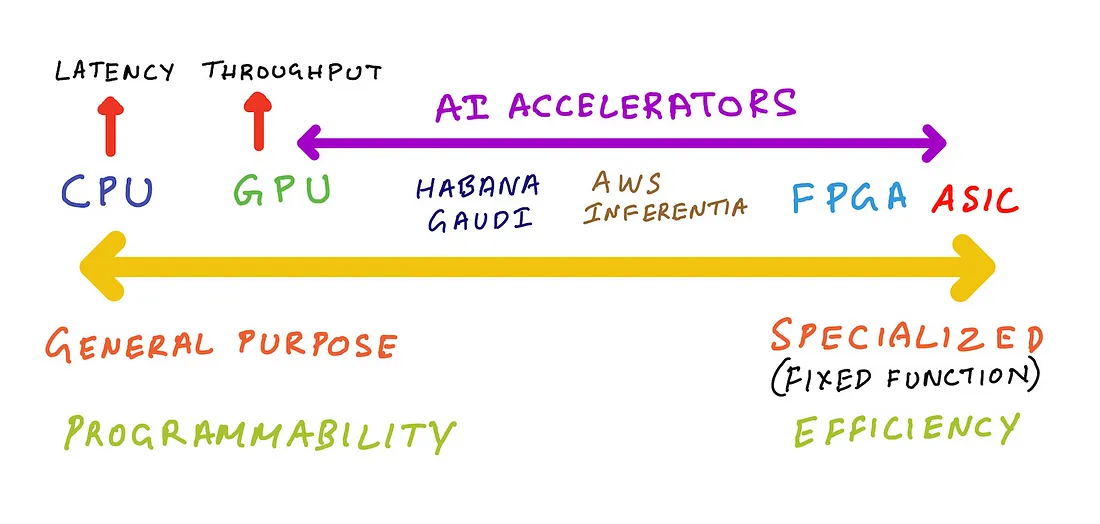
From this reference blog find this quote to explain the above spectrum.
AI accelerators such as Intel Habana Gaudi, AWS Trainium and AWS Inferentia fall somewhere to the right of GPUs. Habana Gaudi offers programmability, but is less versatile than a GPU so we can put it closer to GPUs. AWS Inferentia is not programmable, but offers a list of supported operations it can accelerate, if your machine learning model doesn’t support those operations then AWS Inferentia implements CPU fall back mode for those operations. So, we can put AWS inferentia further right on that spectrum.
Future innovations
As the field of AI and LLMs grow at bottleneck speed, expect more such innovations in single and multi-node accelerators. Probably I will cover them in future posts as I learn more about them.